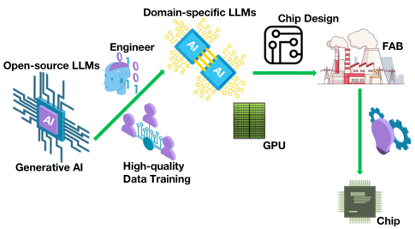
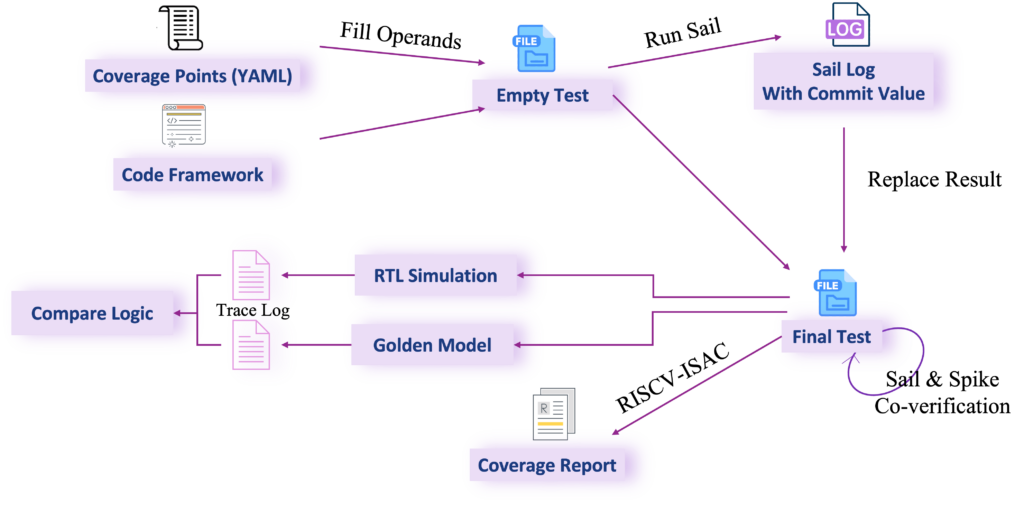
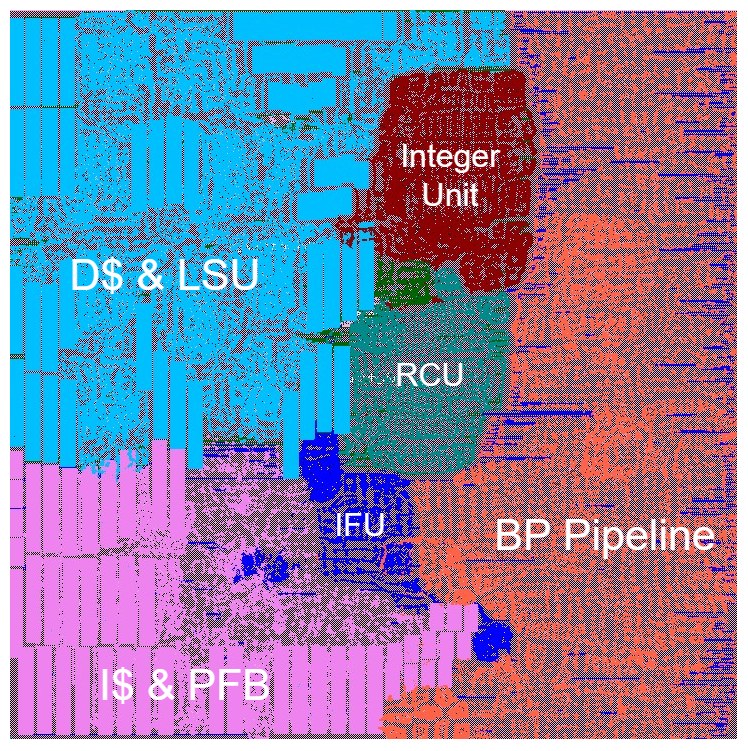
The RISC-V International Open Source Laboratory(RIOS Lab) and RiVAI Technologies, as long-term industry partners, have maintained a close collaboration across research, academia, and industry, continuing to advance joint efforts in the field of high-performance RISC-V processors. Leveraging their respective strengths in scientific research and industrial application, the two sides are jointly accelerating the translation of RISC-V open-source research achievements into innovation and industrial deployment for next-generation high-performance processors.
Under the ongoing collaboration framework, RIOS Lab will continue to leverage its technical expertise in open-source architecture research, advanced system design, and industrial collaboration to provide scientific support and a technical exchange platform for its industry partners, thereby accelerating product development and commercialization. It is reported that RiVAI Technologies plans to officially launch its independently developed high-performance RISC-V processor — LingYu Processor — in the near future. The launch of this product is expected to become an important milestone in RISC-V industry-academia-research collaboration, driving RISC-V high-performance processors in China into a new stage of industrialization.

Meanwhile, RIOS Lab will continue to contribute to the industry by developing talent and establishing standards, promoting the formation of a comprehensive high-performance processor supply chain, performance standards, and testing specifications. The lab aims to accelerate the creation of an independent, secure, and open computing ecosystem, fostering coordinated innovation and sustainable development across the entire industrial chain.
This deepened collaboration further underscores RIOS Lab’s pivotal role in driving open-source processor industrialization and demonstrates the value of integrating research, academia, and industry to achieve breakthroughs in independent chip innovation.
Looking ahead, RIOS Lab will remain committed to its philosophy of openness, collaboration, and co-development, working hand-in-hand with RiVAI Technologies and other ecosystem partners to promote the widespread adoption of RISC-V in high-performance computing, intelligent computing, and emerging technology sectors. Together, the partners aim to build a secure, open, and sustainable global open-source computing ecosystem — contributing China’s strength to the next generation of the computing industry.
RIOS实验室与睿思芯科深化产业合作,共推RISC-V高性能处理器产业化进程
大卫·帕特森RISC-V国际开源实验室(“RIOS实验室”)与睿思芯科作为长期产业合作伙伴,始终保持紧密的产学研协作关系,持续在高性能RISC-V处理器方向展开深入合作。双方依托各自在科研与产业领域的优势,协同推进RISC-V开源成果转化,促进下一代高性能处理器的技术创新与产业落地。
在持续合作框架下,RIOS实验室将发挥自身在开源体系研究、先进架构探索与产业协同方面的技术优势,为产业合作伙伴提供科研支撑与技术交流平台,助力其高性能处理器研发与产品化转化工作。据悉,睿思芯科计划于近期正式发布自主研发的高性能RISC-V处理器——灵羽处理器。该产品的推出预计将成为RISC-V产学研合作的重要里程碑,推动RISC-V高性能处理器在中国进入产业化的新阶段。
同时,RIOS实验室还将继续面向行业输出人才与标准,推动形成基于高性能处理器的产业供应链、性能标准与测试规范体系,加速构建自主、安全、开放的计算生态,促进产业链上下游协同创新与可持续发展。
此次合作的深化,标志着RIOS实验室在开源处理器产业化协同创新中的关键作用进一步显现,也展示了产学研一体化在推动前沿芯片技术自主创新中的重要价值。
未来,RIOS实验室将继续秉持开放、协作、共建的理念,携手包括睿思芯科在内的更多生态伙伴,推动RISC-V在高性能计算、智能算力和新兴产业领域的广泛应用,共同构建安全、开放、可持续的全球开源计算生态,为下一代计算产业的发展贡献“中国力量”。